MPP Database – Pivotal Greenplum
筆者: 歐立威 Hank


1. Database由來:
資料庫是甚麼!?
我們為何需要資料庫!?
相信大家都能說出各家資料庫各式各樣的特色功能,但我想若從”資料庫為我們解決了哪些問題!?”的角度切入,我想大家會對資料庫存在的必要性更有感覺。
在沒有資料庫前,資料以檔案的方式存放,甚至沒有電腦前,資料須以紙張的方式存放…隨著業務增長,資料量多了起來(資料夾層數越來越多、檔案數越來越多或是紙本越來越多…),最常用的搜尋、更改、刪除等功能…
我想大家想到這便頭痛了起來…
所以我們可以很明確的結論出:
“資料庫能夠提供我們更方便、省時的方法去組織與管理企業資料。”,有了資料庫,除了基本的查詢、修改、新增、刪除,更有著許多進階功能如去重複、多用戶權限管理、加解密、備份還原、與其它應用的介接能力…
2. Database硬體架構設計:
隨著企業交易量增長或是大型分析型的資料倉儲的出現,人們發展出不同的架構來解決實務上的問題(圖一):
a. Shared-Everything:
起初隨著交易量的增長,CPU的運算需求增加,最直觀的方法便是在同樣的物理伺服器中放進多個CPU單元,多個CPU之間無主從關係,而擴充的方式不外乎換上更好的CPU或是增加CPU數量等…
共享使得程序間資料交換相當容易,所以Shared Everything相當適合運用在需要高一致性要求的系統中。
共享使得程序間資料交換相當容易,所以Shared Everything相當適合運用在需要高一致性要求的系統中。
但也由於Shared Everything的主要特徵就是共享(共享Memory,
共享Disk
…),當多個CPU存取相同資源時必須等待,所以CPU數量越多,造成的CPU資源浪費也越大,在擴充上是非常有限的,最好的CPU運用效率約莫在2~4個。
b. Shared-Storage:
由於Shared Everything擴充能力上的限制,Shared-Storage算是人們為了解決此問題下的一個成果,其特徵為將多個CPU模塊透過特殊互連模塊組合成一組可擴充的大型系統,每個CPU模塊內有數個CPU與獨立的Memory,CPU模塊則可以透過互連模塊存取其他CPU模塊的Memory。
Shared-Storage雖改善了SMP擴充上的問題,但仍未達到理想的效能與資源量成線性擴充的效果出現,是由於當一個CPU模塊存取其他CPU模塊時仍有干預的狀況發生,且外部儲存空間仍為共享。
在需要多執行序併發的環境下,如傳統交易型資料庫(OLTP),每個CPU僅處理各自獨立作業,當遇上運算資源不足時,Shared-Storage可有效解決此問題,但在需要複雜的運算及大量資料交換下的分析型資料倉儲場景(OLAP),則擴充能力上仍不夠理想,更別說現今所談的需要大量I/O吞吐的巨量資料處理場景。
在需要多執行序併發的環境下,如傳統交易型資料庫(OLTP),每個CPU僅處理各自獨立作業,當遇上運算資源不足時,Shared-Storage可有效解決此問題,但在需要複雜的運算及大量資料交換下的分析型資料倉儲場景(OLAP),則擴充能力上仍不夠理想,更別說現今所談的需要大量I/O吞吐的巨量資料處理場景。
c. Shared-Nothing:
拜網路頻寬技術發展所賜,我們在第三種Shared-Nothing的架構發展有了重大的突破,起初不被看好平行化資料庫軟體系統讓人重新正視。
Shared-Nothing架構是由多個節點透過外部高頻寬交換器連結而成,每個節點有著獨立的CPU、Memory、Disk資源,資料在各節點間交換是透過外部高頻網路達成的,不像Shared-Storage在做非本地資料存取時,會導致其他CPU模塊的等待,除了能將擴充所導致的效能影響降至最低,更能做到真正的多節點資源獨立並達到線性擴充的標準。
由於硬碟容量發展增加速度以遠超過物理磁碟讀寫發展的速度了,透過多個節點各自擁有的多顆硬碟拼湊出來的I/O頻寬更能達到再加上高頻內部交換器的支持,I/O吞吐上的瓶頸也得到了改善,使得Shared-Nothing架構更符合我們在巨量資料時代下發展分析型資料倉儲的需求。

圖一:
資料庫架構設計比較圖
3. MPP Database - Pivotal Greenplum:
再多的理論都需要有產品來實現以解決現實企業中的種種問題,由前述內容我們能了解到因應時代而生的MPP
Database它存在的重要性,Greenplum便是實現MPP架構下的分析型倉儲資料庫,底下我們介紹Greenplum
Database (GPDB) 是如何實現MPP Database的各項重要特性:
a. Shared Nothing Architecture:
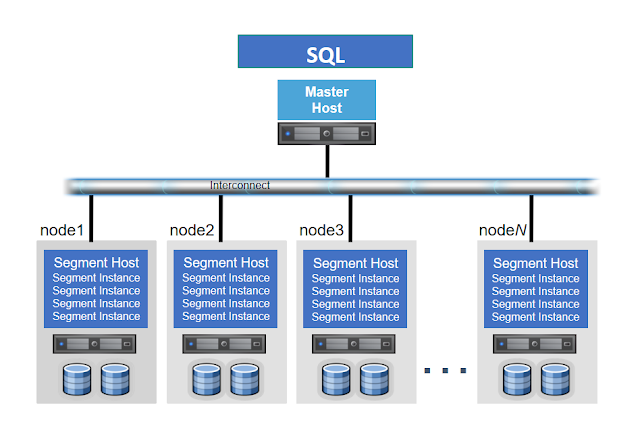
Greenplum是由多台主機組成,並將主機角色分為兩類,一台Master
Host與多台 Segment Host的主從式架構,而每台Segment Host則握有獨立的CPU、Memory、Disk資源
(尤其為大量的硬碟讀寫頻寬),若單台主機資源充足,一台Segment
Host也能起多個Segment Instances更充分地使用所有資源,各Segment Host間透過高頻光纖交換器作為Interconnect,支持大量的資料交換(圖二)。
Master Host為對外的請求接收窗口,能透過ODBC/JDBC介接,由於分布於每個節點instance是由開源Postgres實作,Greenplum
Master的對外窗口也支援所有能夠介接Postgres的應用,如著名的管理工具PSQL或是PGADMIN。
Segment Host則為實際運算及I/O吞吐的節點,請求的結果再透過Master做回應,各自節點的作業互不干擾,符合Shared
Nothing的架構,個節點除了握有獨立的OS、各式資源外,最重要的是都被分配部分的資料(Data
Partitioning),藉此實現平行資料查詢及運算。
Interconncet則為Shared
Nothing架構下的溝通橋梁,Greenplum建議使用標準的10-Gigabit Ethernet光纖交換器,由於在網路層使用TCP協定可能會限制了Greenplum節點擴充上限於1000台左右,所有Greenplum預設使用了UDP協定,但在軟體層內部,Greenplum有自己在封包上驗證機制,可靠性比TCP協定更佳。
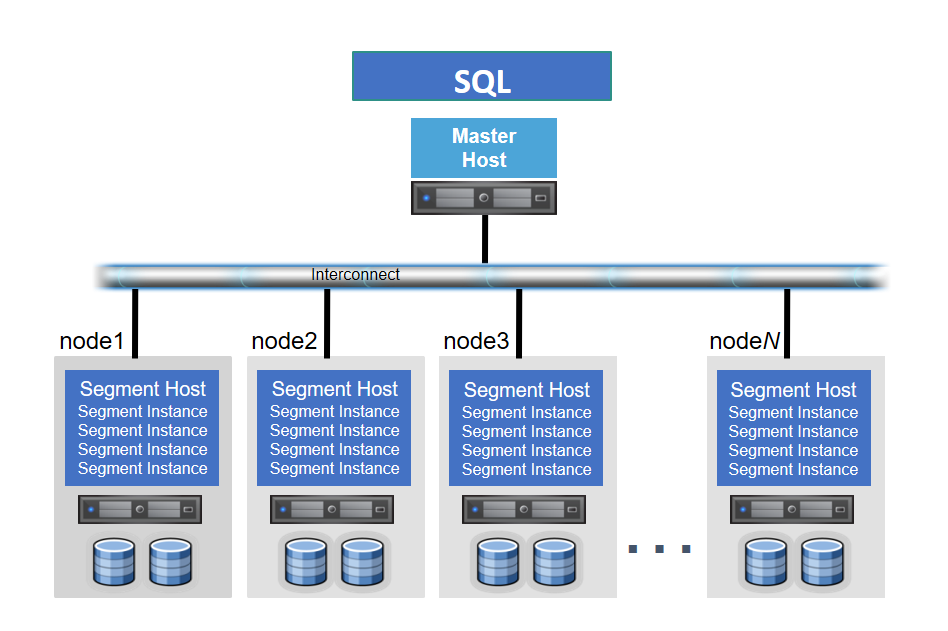
圖二: GPDB
架構圖
b. Easily Scale Out:
由於實現了Shared Nothing的特性,Greenplum在提升效能與儲存量方面都有重大優勢,傳統的資料庫當資源不足時,僅能Scale
Up,來升級其中零件或是將整台機器換掉,舊有的機器只能淘汰,形成了浪費與高金錢本的原因,且更換主機時為了移轉線上資料所耗時間更是不可小覷。
Greenplum除了可以針對每台機器做Scale Up外,更能橫向擴展機器數量來提升整體效能與儲存空間,且由於每個節點資源不共享,更能達到效能與儲存量完美的線性增長效果。
在橫向擴展時,優點不單只是加入新機器與簡單更改設定而已,還能夠Online的做資料重分布,以減少資料庫的down time,時間與金錢成本比起傳統資料庫相當有優勢(圖三)。
在橫向擴展時,優點不單只是加入新機器與簡單更改設定而已,還能夠Online的做資料重分布,以減少資料庫的down time,時間與金錢成本比起傳統資料庫相當有優勢(圖三)。

圖三:
GPDB線性節點擴充
c. Parallel Querying:
MPP繼承了Shared-Nothing,各節點間資源不共享,此外,資料也以某些邏輯切割分布在每個節點上,每個節點握有獨立不共享的資料集,負責該資料集查詢、計算等操作。
當GPDB Master接收到一個Query時,會為該Query產生優化過的執行計劃,並發送給每個Segment,每個Segment針對自身握有的獨立資料集作操作,並依照執行計劃查出做最有效率的平行運算,找出符合條件的資料再回饋給Master。
因為每台機器握有獨立資料及獨立資源,整體的效率取決於最後完成任務的Segment,所以說Greenplum資料的平均分布、表單結構設計或是查詢語法的撰寫都是十分重要的課題,目的是希望每個主機都能分配到相同的工作量以便在近乎同時間內完成,進而在整體平行運算下達到最好的效能(圖四)。
當GPDB Master接收到一個Query時,會為該Query產生優化過的執行計劃,並發送給每個Segment,每個Segment針對自身握有的獨立資料集作操作,並依照執行計劃查出做最有效率的平行運算,找出符合條件的資料再回饋給Master。
因為每台機器握有獨立資料及獨立資源,整體的效率取決於最後完成任務的Segment,所以說Greenplum資料的平均分布、表單結構設計或是查詢語法的撰寫都是十分重要的課題,目的是希望每個主機都能分配到相同的工作量以便在近乎同時間內完成,進而在整體平行運算下達到最好的效能(圖四)。

Comments
Post a Comment